创建数据库
SQL:
1
|
CREATE DATABASE [IF NOT EXISTS] db_name [[DEFAULT] CHARSET=charset_name] [[DEFAULT] COLLATE=collation_name];
|
其中,大写的单词是关键字,使用时可以不大写, MySQL 会进行语法优化(本系列主要用小写,一是方便,二是可读性较好);[] 中表示可选项;SQL 必须以;结尾。
- CHARSET:指定数据库采用的编码格式。
- COLLATE:指定数据库采用的校验规则。
如果在创建数据库时未制定编码格式或校验规则,MySQL 则使用配置文件中对应的默认选项。
直接创建名为test_db1的数据库,不指定其他属性:
1
2
|
mysql> create database test_db1;
Query OK, 1 row affected (0.00 sec)
|
创建数据库后,可以用USE <database_name>来打开数据库(实际上是进入这个数据库所在的目录)。
字符集和校验规则
概念
在 MySQL 中,字符集和校验规则决定了 MySQL 如何存储和比较字符串。简单地说:
- 字符集是一套字符与编码的映射集合,字符集就是编码文字的格式,和语言有关,它决定了 MySQL 如何存储和显示字符串;
- 校验规则是一套字符之间的比较规则,它决定了 MySQL 如何排序和比较字符串。校验规则会影响到 ORDER BY 语句的顺序,会影响到 WHERE 条件中大于小于号筛选出来的结果,会影响 DISTINCT、GROUP BY、HAVING 语句的查询结果。
不同的语言和场景可能需要不同的字符集和校验规则,所以 MySQL 允许用户自己选择或者指定。不同的字符集和校验规则会影响 MySQL 的性能和兼容性。
如果把字符集和校验规则比作是一本字典,那么:
- 字符集就是字典里面的字母表,它告诉你每个字母对应的编码是什么。
- 校验规则就是字典里面的排序规则,它告诉你如何按照字母顺序排列单词。
不同的语言可能有不同的字母表和排序规则,所以你需要选择合适的字典来查阅或者编写文字。
分类
字符集可以分为单字节字符集和多字节字符集,例如 ASCII、Latin1、GB18030、UTF8 等。每种字符集都有一个或多个校验规则,例如 utf8_general_ci、utf8mb4_0900_ai_ci 等。校验规则的命名通常遵循以下约定:
- 以字符集名开头,如 utf8、gbk 等。
- 以国家名或 general 居中,如 chinese、swedish、general 等。
- 以 ci、cs 或 bin 结尾,分别表示大小写不敏感(case insensitive)、大小写敏感(case sensitive)或按二进制比较。
不同的校验规则有不同的性能和准确性,一般来说,以 _unicode_ci 结尾的校验规则比以 _general_ci 结尾的校验规则更准确,但也更慢。以 _bin 结尾的校验规则是按照编码值比较,所以是大小写敏感的。
MySQL 中可以为不同的层次设置字符集和校验规则,例如服务器层、数据库层、表层和列层。可以通过SHOW VARIABLES LIKE 'character_set_database' 和 SHOW VARIABLES LIKE 'collation_set_database' 命令查看当前 MySQL 使用的字符集和校验规则。如果要修改某个层次的字符集或校验规则,可以使用 ALTER 命令或者在创建时指定。
例如查看test_db1的字符集和校验规则:
1
2
3
4
5
6
7
8
9
10
11
|
mysql> USE test_db1; # 进入数据库
mysql> SHOW VARIABLES LIKE 'character_set_database';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| character_set_database | utf8 |
+------------------------+-------+
1 row in set (0.00 sec)
mysql> SHOW VARIABLES LIKE 'collation_set_database';
Empty set (0.00 sec)
|
注意,如果不使用USE关键字进入数据库test_db1,查看的就是 MySQL 默认的字符集或校验规则。
由于在创建时没有指定校验规则,所以这个数据库的校验规则是空,也就是没有默认的校验规则。
为什么 MySQL 没有默认的校验规则?每一个字符集都有一个或多个校验规则?
MySQL 没有默认的校验规则是因为不同的字符集和场景可能需要不同的校验规则,所以 MySQL 允许用户自己选择或者指定校验规则。校验规则会影响到字符串的存储、排序、比较和索引等操作,所以用户需要根据自己的需求来选择合适的校验规则。
例如,如果用户需要存储多种语言的字符串,或者需要区分大小写和重音等细节,那么可以选择 utf8mb4_unicode_ci 这样的校验规则。如果用户只需要存储中文或者英文,或者不关心大小写和重音等细节,那么可以选择 utf8mb4_general_ci 这样的校验规则。不同的校验规则会有不同的性能和准确性,所以用户需要权衡利弊,选择最适合自己的校验规则。
如果用户没有指定校验规则,那么 MySQL 会使用字符集对应的默认校验规则。例如在 MySQL5.7 中,utf8 字符集对应的默认校验规则是 utf8_general_ci。这样可以保证字符集和校验规则之间的一致性,避免出现乱码或者错误的比较结果。
查看数据库支持的字符集或校验规则:
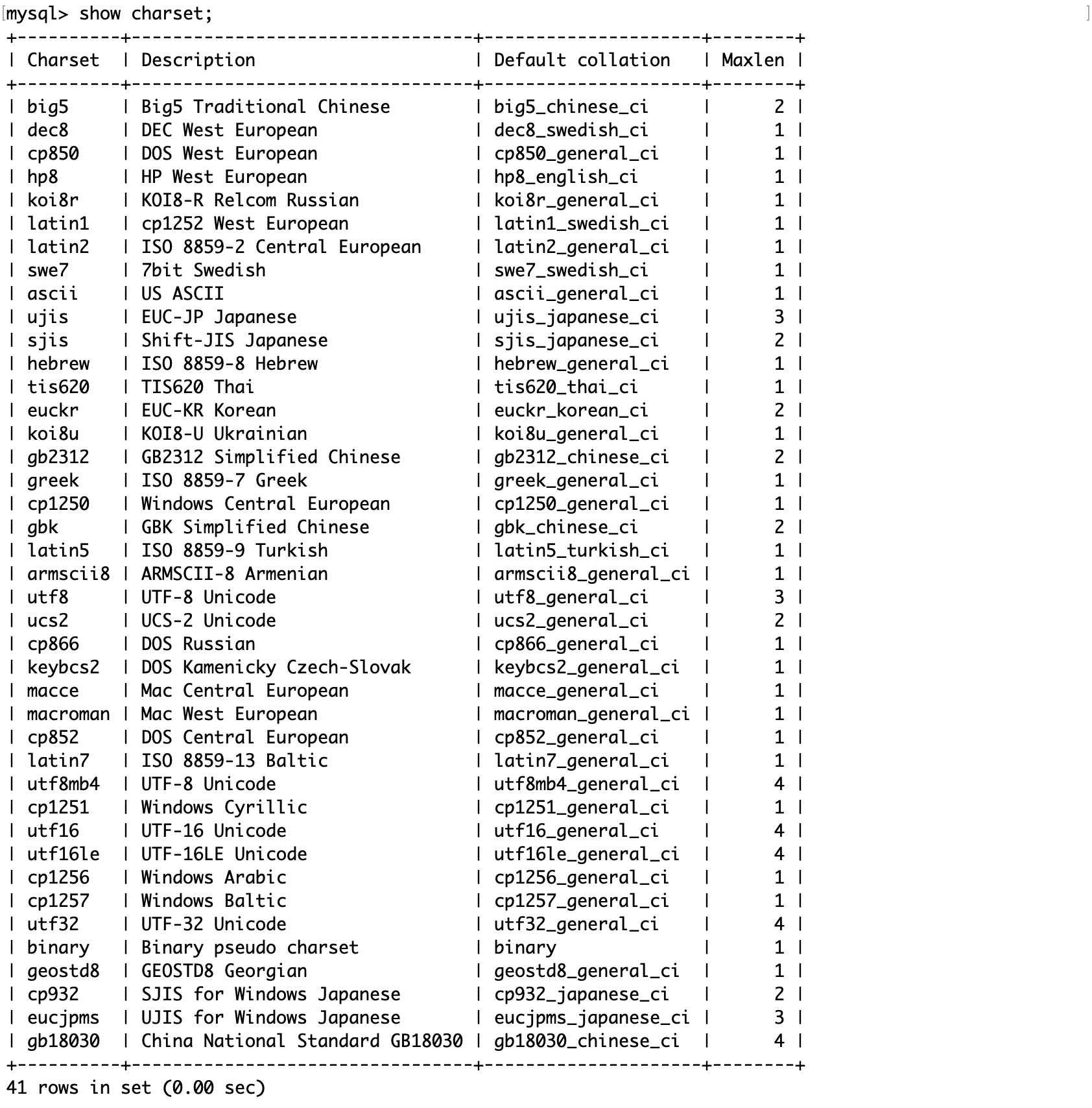
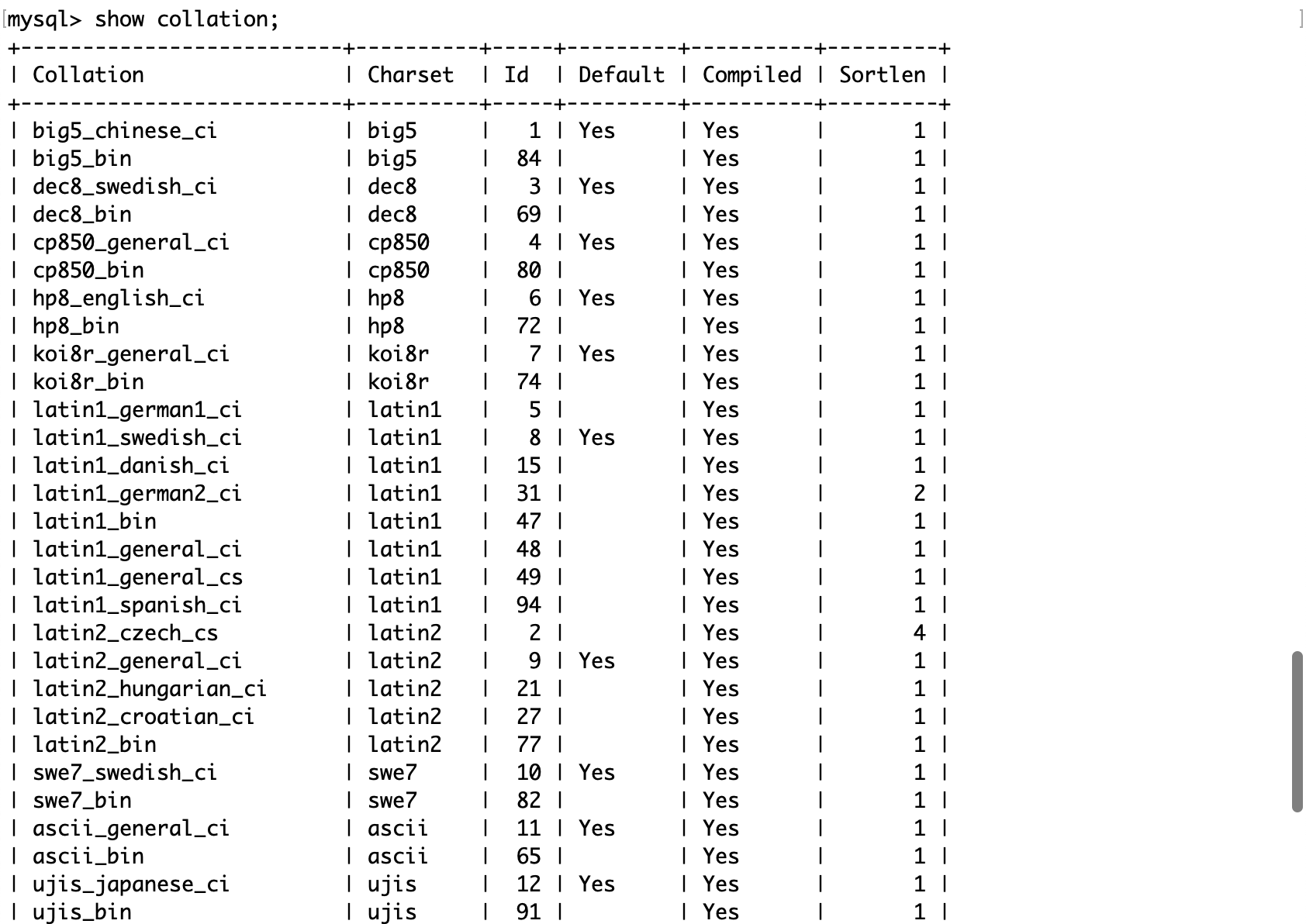
例子
有字符集(编码格式)我可以理解,毕竟不同语言需要不同的格式,这样才不会显示乱码。但是校验规则存在的意义在哪里呢?
在演示例子之前,我们再用 摩尔斯电码 来类比:摩尔斯电码用点和划的不同组合,来表示 A~Z 这 26 个字母,从而实现非文字通信。那么发送和接收信息的过程,都需要按照这同一套规则来编码和解码。数据库在很多时候都是作为查询使用的,那么在查询时,实际上也是通过“对比”这个操作来查找的。如果查询的规则和写入的规则不一样,就算有这条数据,也无法找到。
上文提到,每个字符集都有一个或多个校验规则,这么做的原因是一种语言可能有不同的形式,以起到不同的作用。
下面以 utf8_general_ci 校验规则来创建一个person_test1数据库,并创建一个person1表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
# 创建数据库
mysql> create database person_test1 collate=utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
# 进入数据库
mysql> use person_test1;
Database changed
# 创建表
mysql> create table person1(
-> name varchar(20)
-> );
Query OK, 0 rows affected (0.02 sec)
# 插入两行数据
mysql> insert into person1 values ('AAAAA');
Query OK, 1 row affected (0.01 sec)
mysql> insert into person1 values ('aaaaa');
Query OK, 1 row affected (0.00 sec)
# 输出表中的内容
mysql> select * from person1;
+-------+
| name |
+-------+
| AAAAA |
| aaaaa |
+-------+
2 rows in set (0.00 sec)
|
查找名为aaaaa或者AAAAA的数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
mysql> select * from person1 where name='aaaaa';
+-------+
| name |
+-------+
| AAAAA |
| aaaaa |
+-------+
2 rows in set (0.00 sec)
mysql> select * from person1 where name='AAAAA';
+-------+
| name |
+-------+
| AAAAA |
| aaaaa |
+-------+
2 rows in set (0.00 sec)
|
由此可见,utf8_general_ci 不是大小写敏感的。可以用同样的方式创建数据库person_test2测试,utf8_general_cs 是大小写敏感的。
用这个语句查看某个数据库中某个表的字符集和比较规则:
1
|
select table_schema, table_name, table_collation from information_schema.tables where table_schema ='person_test1'and table_name='person1';
|
1
2
3
4
5
6
|
+--------------+------------+-----------------+
| table_schema | table_name | table_collation |
+--------------+------------+-----------------+
| person_test1 | person1 | utf8_general_ci |
+--------------+------------+-----------------+
1 row in set (0.00 sec)
|
同样地,以 utf8_bin 校验规则来创建一个person_test3数据库,并创建一个person3表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
mysql> create database person_test3 collate=utf8_bin;
Query OK, 1 row affected (0.00 sec)
mysql> use person_test3;
Database changed
mysql> create table person1( name varchar(20) );
Query OK, 0 rows affected (0.02 sec)
mysql> insert into person1 values ('aaaaa');
Query OK, 1 row affected (0.00 sec)
mysql> insert into person1 values ('AAAAA');
Query OK, 1 row affected (0.00 sec)
mysql> select * from person1;
+-------+
| name |
+-------+
| aaaaa |
| AAAAA |
+-------+
2 rows in set (0.00 sec)
mysql> select * from person1 where name='AAAAA';
+-------+
| name |
+-------+
| AAAAA |
+-------+
1 row in set (0.00 sec)
mysql> select * from person1 where name='aaaaa';
+-------+
| name |
+-------+
| aaaaa |
+-------+
1 row in set (0.00 sec)
|
由此可见,utf8_bin 不是大小写敏感的,因为它按照二进制比较。
查看数据库
使用:
来查看当前 MySQL 服务器中的所有数据库:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| person_test1 |
| person_test2 |
| person_test3 |
| sys |
| test_db1 |
+--------------------+
8 rows in set (0.00 sec)
|
显示创建语句
1
|
show create database <database_name>;
|
在前面增加show关键字,可以查看数据库是如何执行 SQL 来创建数据库的。

虽然我们输入时是用小写的关键字,但是 MySQL 会自动对用户输入的 SQL 做语法优化,将小写的关键字用大写字母代替,而且数据库的名字会用`(反引号,在 esc 下面)来包含,这么做是方式数据库的名称和关键字冲突。
另外,如果用户输入的 SQL 由多行组成,MySQL 会将;之前的所有字段合并为一句。
例如上面在创建表时,为了可读性,用了多行输入,但 MySQL 会优化如下:

另外,MySQL 也有记忆指令的功能:

注意,/*!40100 DEFAULT CHARACTER SET utf8 */不是注释,它表示当前 MySQL 版本如果大于 4.10,则执行后面的 SQL 语句。
MySQL 客户端会阻塞当前会话,如果不想新建会话的同时使用系统的命令行,可以在命令行指令前加system,例如:
1
2
|
system clear # 清屏
system ls -l
|
修改数据库
SQL:
1
|
ALTER DATABASE db_name [[DEFAULT] CHARSET=character_name] [[DEFAULT] COLLATE=collation_name];
|
对数据库修改的内容主要是字符集和校验规则。
例如,将person_test1数据库的字符集改成 gbk,校验规则改为 gbk_bin:
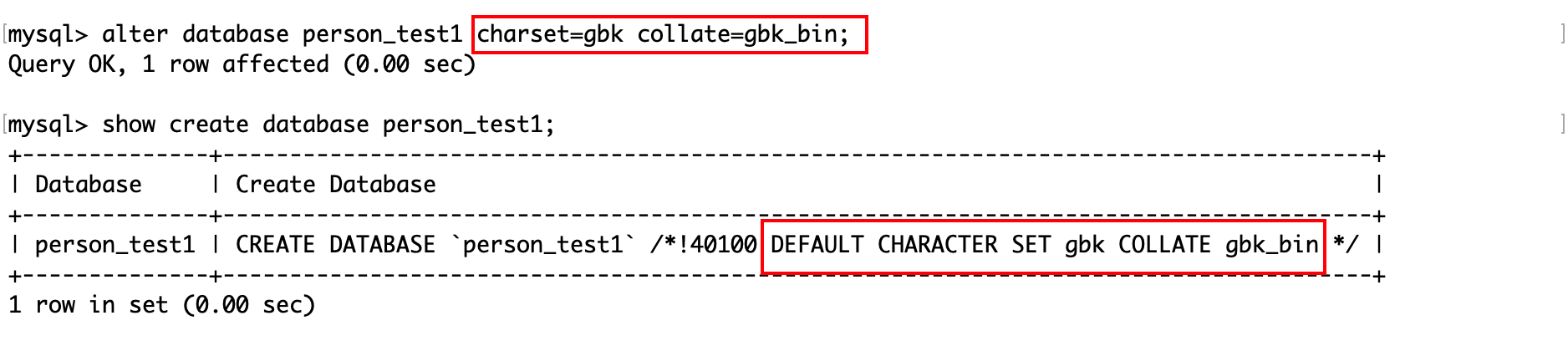
删除数据库
SQL:
1
|
DROP DATABASE [IF EXISTS] db_name;
|
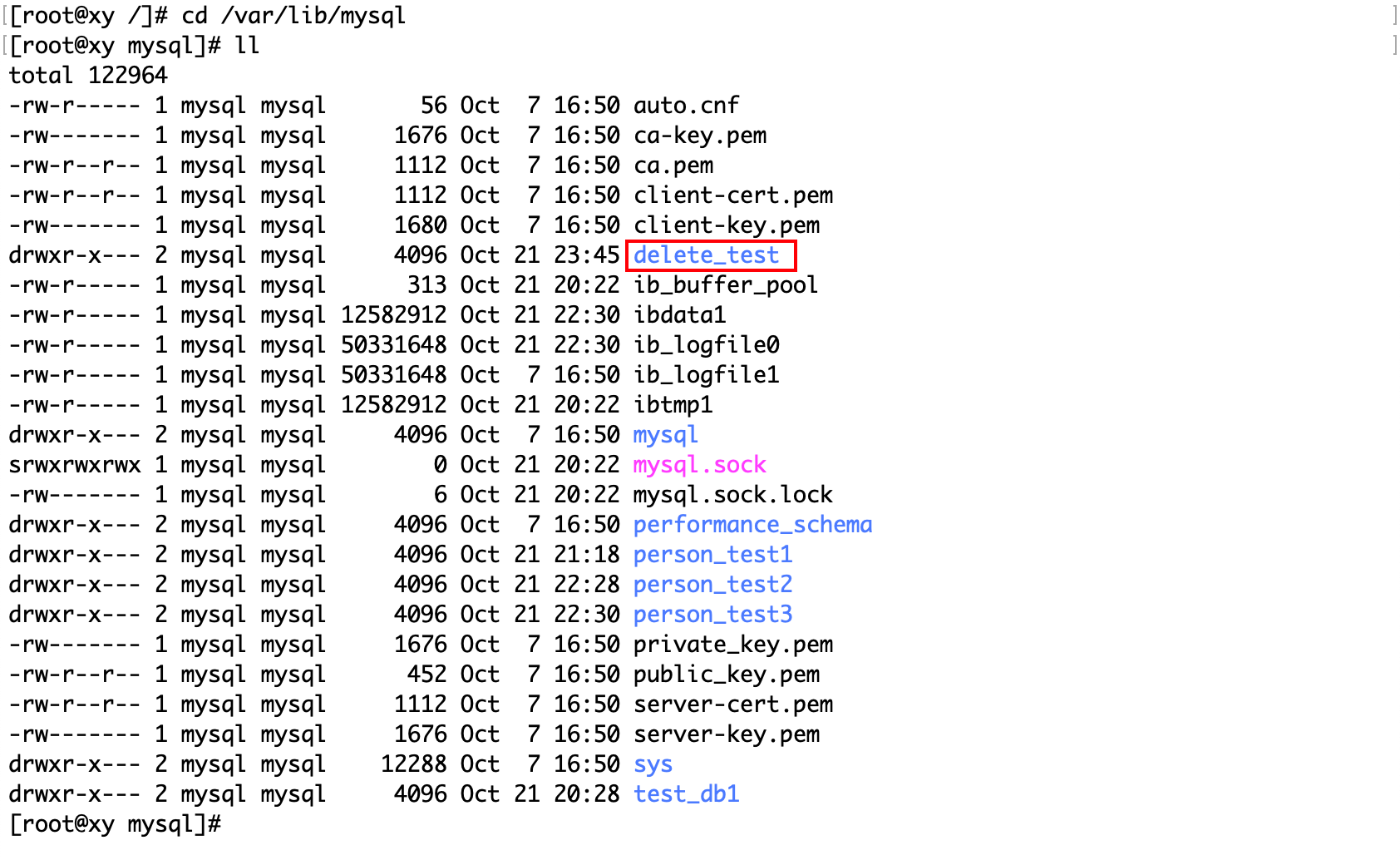
创建一个数据库:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
mysql> create database delete_test;
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| delete_test |
| mysql |
| performance_schema |
| person_test1 |
| person_test2 |
| person_test3 |
| sys |
| test_db1 |
+--------------------+
9 rows in set (0.00 sec)
|
删除它:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
mysql> drop database delete_test;
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| person_test1 |
| person_test2 |
| person_test3 |
| sys |
| test_db1 |
+--------------------+
8 rows in set (0.00 sec)
|
当删除这个数据库后,这个路径下的同名目录也会被删除,即使里面有表。
备份和恢复
备份
命令行:
1
|
mysqldump -P 端口号 -u 用户名 -p 密码 -B 数据库名 1 数据库名 2 ... > 数据库备份存储的文件路径
|
创建一个数据库,并在里面创建两个表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
mysql> create database backup_test;
Query OK, 1 row affected (0.00 sec)
mysql> use backup_test;
Database changed
mysql> create table teacher(
-> age int,
-> name varchar(20)
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> create table student(
-> age int,
-> name varchar(20)
-> );
Query OK, 0 rows affected (0.01 sec)
|
在这两个表中分别插入两条记录:
1
2
3
4
5
6
7
8
9
10
11
|
mysql> insert into teacher values (24, '李老师');
Query OK, 1 row affected (0.01 sec)
mysql> insert into teacher values (34, '王老师')
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values (13, '小明');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values (12, '小陈');
Query OK, 1 row affected (0.00 sec)
|

在 Linux 命令行中(MySQL 是我创建的一个目录):
1
|
[root@xy MySQL]# mysqldump -P3306 -uroot -p -B backup_test > back.sql
|
这个文件保存了对数据库和表的所有 SQL 操作以及数据本身,并且是做了优化的:

恢复
SQL:
为了方便演示,将原来的数据库删除,然后再恢复。
1
|
mysql> source /home/xy/MySQL/back.sql;
|

这样数据库中的所有内容都恢复了。
由此可见,数据库的备份就是将 MySQL 之前优化并记录的 SQL 语句拷贝一份;恢复就是将这些 SQL 语句交给 MySQL 服务器重新执行一遍。
注意,备份是服务端做的,而恢复是在客户端做的。
备份表的操作也是一样的,只不过需要在需要恢复的数据库中操作。